Private Preview
Applications open for litigation teams at firms handling federal matters.
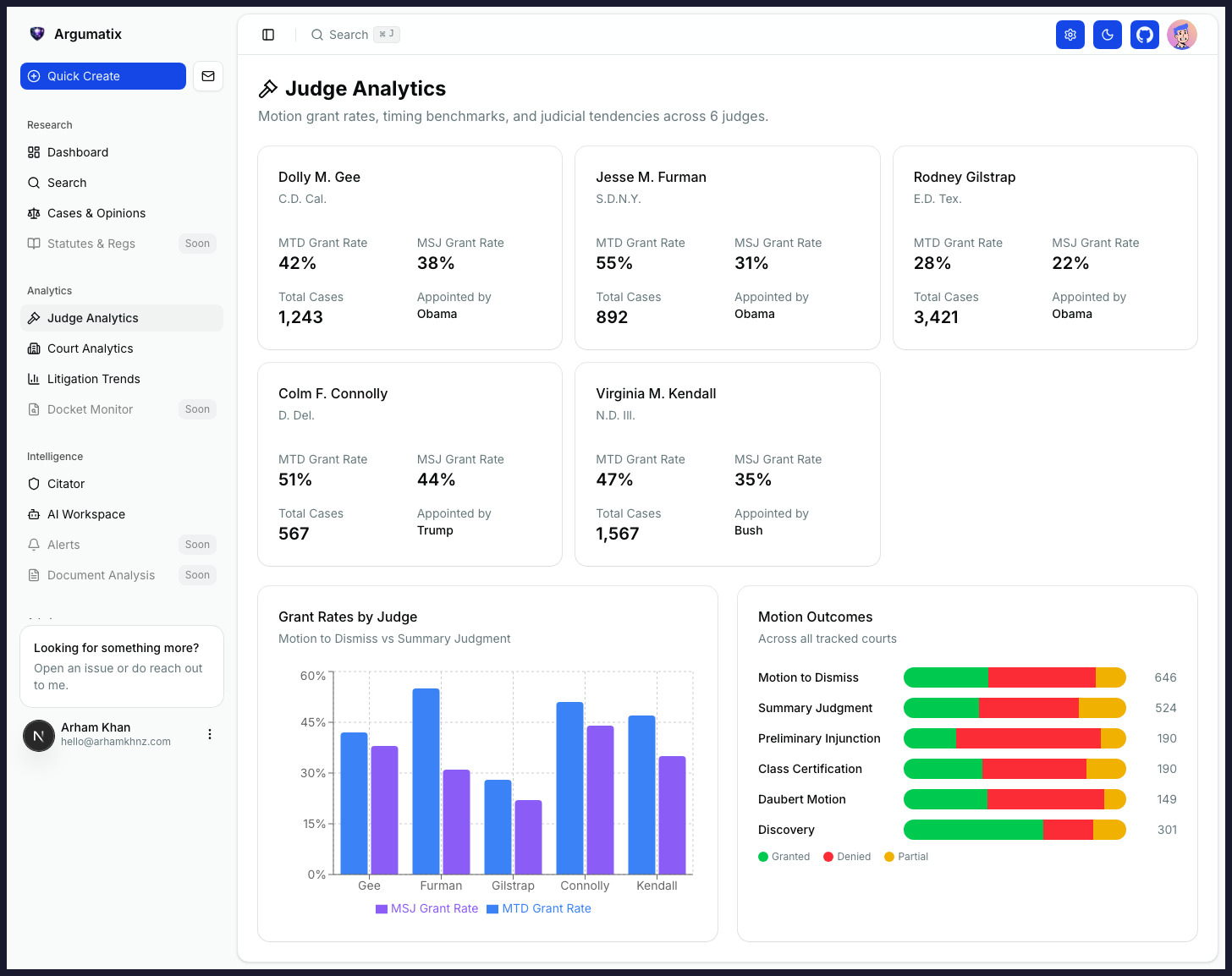
Argumatix turns the entire federal docket into causal, source-traced intelligence — so you know what moves your judge before you file. Treatment effects, not correlations. Every claim tied to the document it came from.

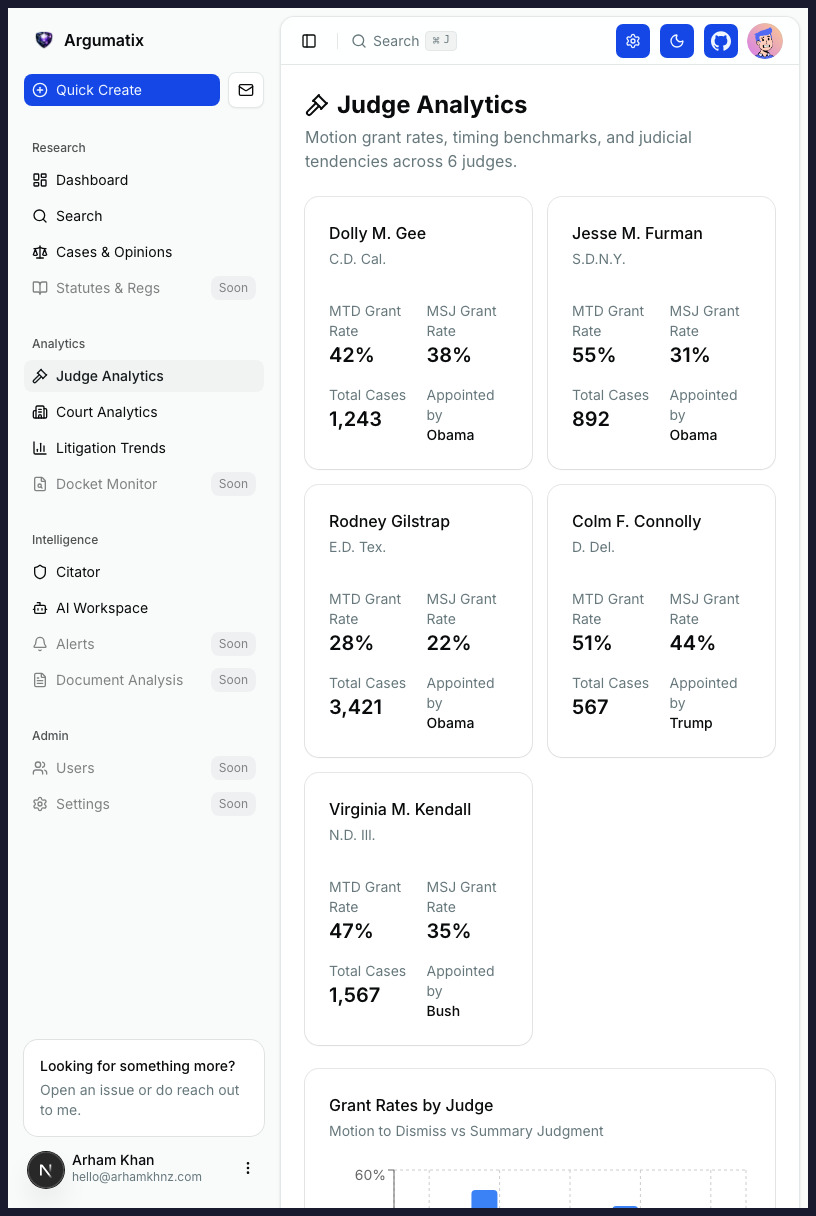
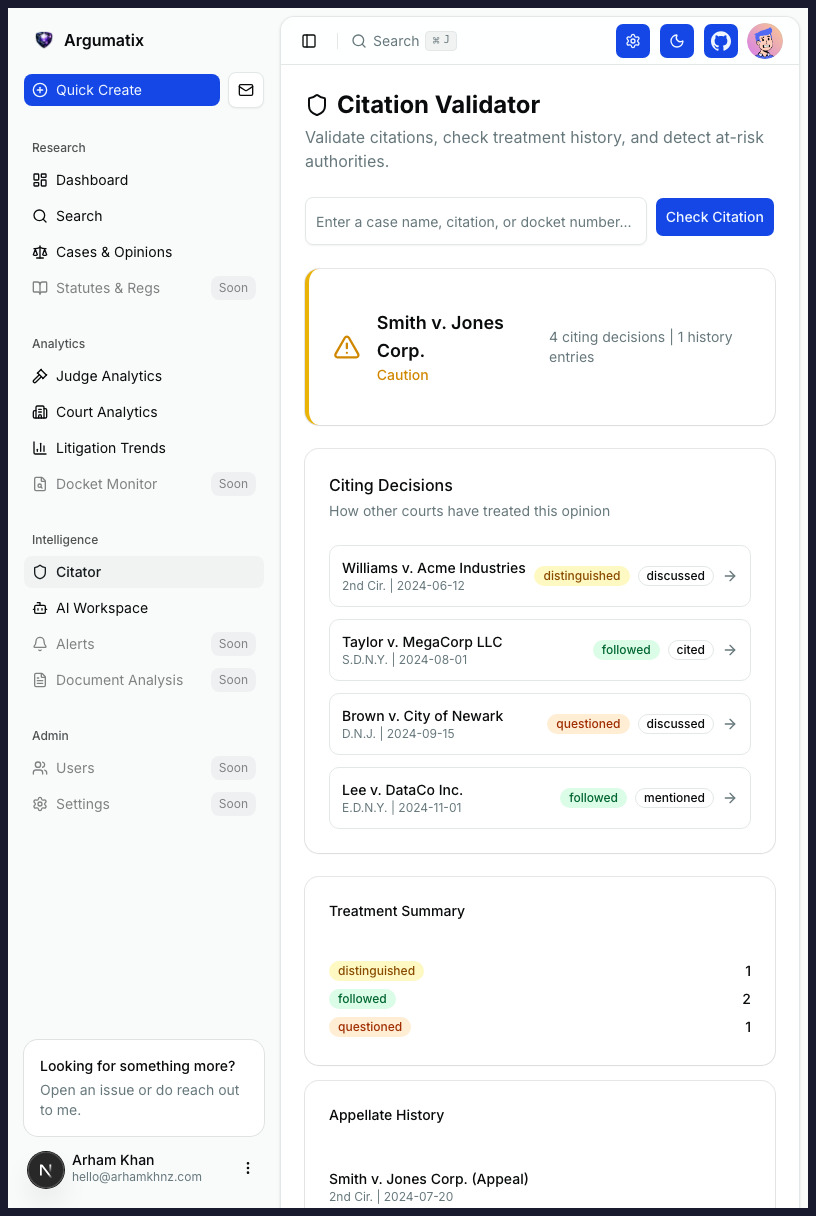
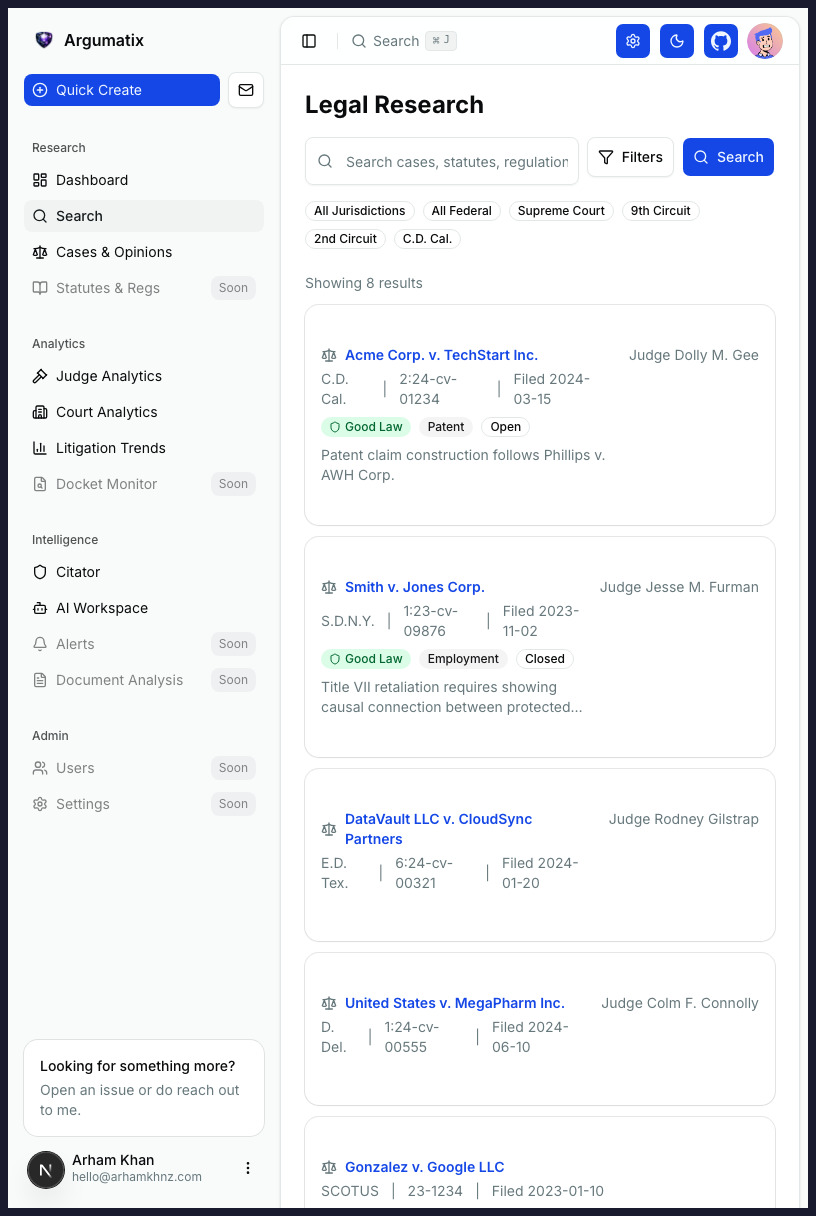
Before you file, see the adjusted causal effect of every procedural choice before this judge, the specific language from prior briefs your judge adopted into orders, and the full behavioral playbook of opposing counsel in this courtroom. Every data point traces back to a court document you can open.
Argumatix composes seven specialized engines — each solving a different slice of federal litigation — into a single, source-traceable answer for every decision you make.
Staged predictions calibrated to each judge. See filing-time odds today, then the post-briefing refinement once your reply is in — not a single number dressed up as precision.
Doubly-robust treatment effects, heterogeneous by judge, gated by refutation tests. We answer "what changes if you file the reply?" — not "what correlates with winning."
We match the propositions in your brief against the exact language your judge has adopted — or rejected — from prior briefs. See what framings survive, verbatim, in this courtroom.
Argumatix forecasts the full trajectory — complaint, PMC, MTD, discovery, MSJ, settlement — with timing and leverage windows for each phase. An Expected-Value engine attaches settlement probability, damages distributions, and fee-shifting economics to every move, so you can rank decisions by EV delta, not gut feel.
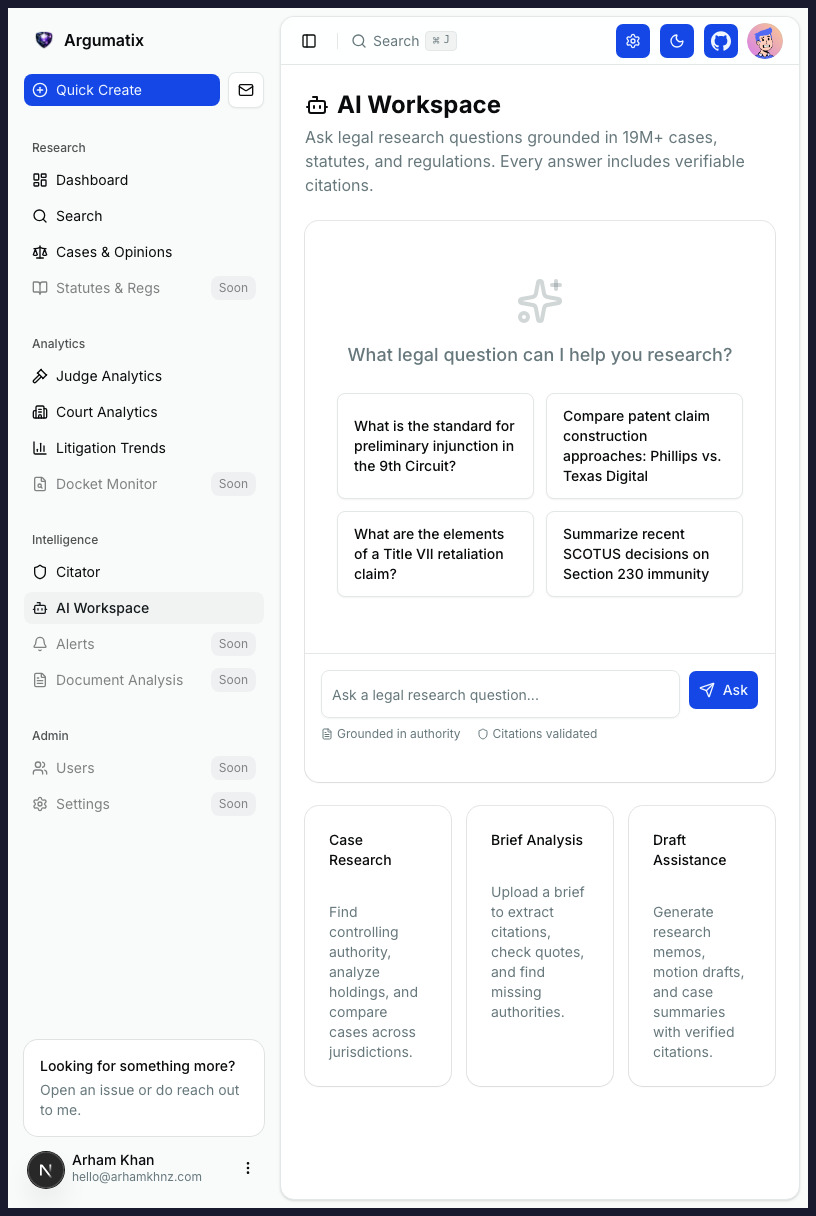
Generic research tools surface correlations. Argumatix adjusts for confounders and gates every recommendation on a refutation test — so the number you see is the number you can act on.
A raw association mined from opinions. It can't tell you whether replies caused better outcomes or whether the stronger cases were simply the ones that got replies.
A doubly-robust treatment effect, estimated per judge, with heterogeneity explored and sensitivity refutations documented. Below our confidence floor, the recommendation is suppressed — not hidden with a confidence interval that pretends to be precise.
Illustrative preview. Your dashboard returns effect estimates specific to the judge, motion type, and case features of your actual matter.
Argumatix ingests and structures federal court data from CourtListener, RECAP, and PACER, cross-referenced with SEC EDGAR, FDA, and CFPB for regulatory context. No proprietary legal databases. No black-box licensing. Every pipeline is continuously evaluated with synthetic negative controls so that drift is caught before it reaches you.
LLMs are scoped to narrow extraction tasks with schema validation and byte-exact span grounding — never free-form generation. Predictive models are calibrated per-judge and abstain when evidence is thin. The cold, boring discipline that makes intelligence trustworthy at scale.
Argumatix ingests and structures data from authoritative public legal sources, continuously.
The official electronic public access service of the United States federal judiciary. Docket entries, filings, and case records from all 94 federal district courts.
The largest structured collection of judicial opinions available. Full-text opinions, oral arguments, and comprehensive citation networks spanning federal and state courts.
The official repository of corporate filings for every public company in the United States. 10-K, 10-Q, S-1, proxy statements, and insider transaction records.
The research and education agency of the U.S. federal courts. The Integrated Database covers every federal civil case filed since 1970 — the gold standard for litigation analytics.
Federal enforcement actions, product recalls, warning letters, and compliance data. Essential for pharmaceutical litigation, product liability, and regulatory dispute research.
The daily journal of the United States Government. Proposed rules, final rules, executive orders, and agency notices — the authoritative source for all federal regulatory activity.

"I built Argumatix because I believed the most valuable legal data was already public — it just needed the right engineering and AI to become truly useful."